VRU tracking in LiDAR point cloud
1. Background
The background of this project is to develop a pipeline for high quality ground truth data production for pedestrian tracking in LiDAR point cloud data. In the context of urban autonomous driving, tracking different types of road users is crucial for safe and efficient navigation.

In dense VRU (Vulnerable Road User) scenarios, tracking challenges often arise due to obstructions, local multiple VRU interactions, such as adults leading children or multiple people walking side by side(see figure below). Traditional tracking methods based on point cloud clustering, registration or motion models often fall short in addressing these issues. Hence, a data-driven approach is embraced, by learning sequences of point cloud data to predict the motion of the target. This project focuses on exploring spatio-temporal relationships within point cloud data to address these challenges.

2. Challenges Faced
- Irregularity of pedestrian motion patterns, such as sudden stops, turns, and interactions with other pedestrians.
- Sparse point cloud data due to partial occlusion or when the target is distant from the self-driving vehicle.
- Point cloud data from other objects in the environment interfering with target object, especially when the target is walking near walls, under trees, or beside shrubs.
3. Proposed Solution
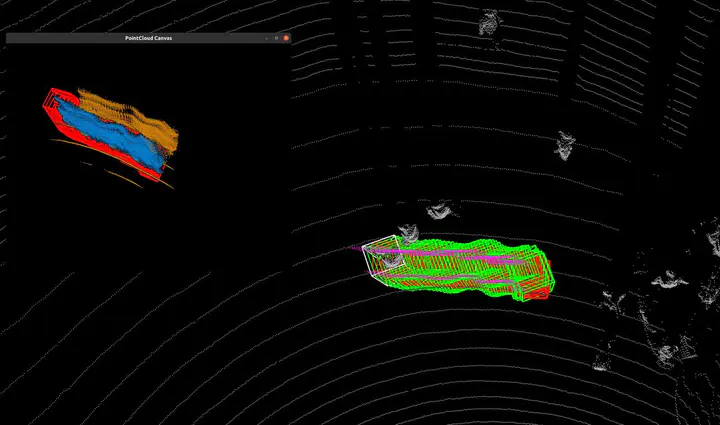
- We developed a human in the loop annotation strategy to generate high quality ground truth data for pedestrian tracking in LiDAR point cloud data. Which includes using rule based algorithms to propose seed points for annotators to refine and correct. Data driven models based on deep learning are then used to predict the motion of the target object in the next frame. Ground truth data from human annotators is used to train the model, and the model is then used to predict the motion of the target object in the next frame. The predicted motion is then used to refine the tracklet frames in a Sequence to Sequence manner. The model is designed to segment the target object from the point cloud data, and predict the motion of the object in the next frame, the training task is formulated as a sequence to sequence problem, where the input is seed point cloud data from a sequence of frames, and the output is a sequence of segmented point cloud data and a sequence of predicted motion of the target object in the form of 3D bounding boxes.

As shown in the figure above, the input sequence of point clouds are in different colors, and the output are bounding boxes in different colors. The input sequence of point clouds are used to predict the motion of the target object in the input sequence, and the predicted motion is used to refine the tracklet frames in a Sequence to Sequence manner.
4. Model Training & Deployment
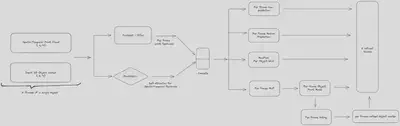
This model is trained with data collected with human in the loop annotation strategy, and evaluated on a test set collected with the same strategy. A front end tool based on Three.js is developed to visualize the tracking results in 3D space. The data collection pipeline consist of both automatic and manual annotation steps, during the automatic annotation step, a motion model based algorithm is used to propose seed points using 3D bounding boxes for annotators to refine and correct. The manual annotation step is done by human annotators, who are trained to annotate the target object in the point cloud data. The annotated data is then used to train the model, and the model is then used to predict the motion of the target object in the next frame. Therefore, with more annotated data in different scenarios, the model can be trained to predict the motion of the target object for more various scenarios.
During training various augmentation techniques are used to improve the model’s generalization ability. This include augmentaion techniques for point cloud sequences, such as random rotation, scaling, and translation, and random point sampling to adapt different types of LiDARs. Also, augmentation techniques for temporal data, such as random frame dropping, and random frame shuffling.
The model is then deployed as a service, where it can be used to predict the motion of the target object in real time. During the annotation step, the model is used to predict the motion of the target object in the next frame, the annotator can also refine a sequence of frames with a single click, and the model will refine the tracklet frames sequentially. The model is designed to be scalable, and can be deployed on a cluster of GPUs to handle large amount of data concurrently.
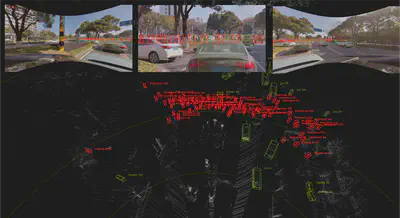
5. Demo
Our model uses input seed points provided by human annotators or point cloud detection models to determine the 3D bounding box of an object in the initial frame. Subsequently, it iteratively refines and predicts the bounding box for successive frames. Essentially, the tracking procedure is distilled into an autoregressive task of predicting the object’s center position, complemented by a segmentation head that identifies the object’s mask in the point cloud sequence.
This project is done at NIO Inc. in the year of 2023.
Chengqi (William) Li
My research interests include 3D perception, computer vision, and deep learning.