Image-Pretrained Vision Transformers for Real-Time Traffic Anomaly Detection
Motivation
Traffic anomaly detection (TAD) is critical for autonomous driving, requiring both high accuracy and low latency. The task involves identifying abnormal or dangerous events from ego-centric dashcam footage in real-time, framed as a binary classification problem at the frame level.
Recent work such as Simple-TAD shows that a simple encoder-only VideoMAE model with strong pre-training can outperform complex multi-stage architectures, achieving 85.2% AUC-ROC on the DoTA benchmark. However, video-pretrained models like VideoMAE process 3D spatiotemporal tokens, making them computationally expensive for edge deployment.
Can we trade some accuracy for significantly faster inference by using lighter, image-pretrained backbones instead?
Approach: VidEoMT-TAD
We adapted the backbone of VidEoMT, a video instance segmentation model, for TAD. Instead of a video foundation model, we use a frame-based image foundation model (DINOv2) and handle temporal modeling through lightweight query propagation.
Core mechanism (EoMT): Instead of a separate decoder, learnable query tokens are injected directly into the encoder’s self-attention layers alongside patch tokens. VidEoMT extends this to video by propagating queries across frames, allowing them to accumulate cross-frame semantic information without any dedicated temporal encoder.

The architecture works in three stages:
Frame-independent encoding: Each frame is processed independently through a DINOv2 ViT-S/14 backbone, producing 14x14 = 196 patch tokens per frame.
Query-based cross-attention: Learnable query tokens attend to patch features via cross-attention in transformer blocks 9-11. This is where the model learns what to look for in each frame.
Temporal aggregation: Queries are propagated across frames using a GRU-based updater, enabling the model to track evolving patterns across time. The final frame’s query representation is used for binary classification.
For multi-query configurations (Q > 1), we aggregate per-frame queries via max pooling, which preserves the strongest response per feature, since anomalous events tend to strongly activate specific queries.

Key Findings
Self-supervised pretraining matters most
We compared different backbone initializations under controlled settings:
| Pretraining | AUC-ROC | FPS |
|---|---|---|
| DINOv2 (self-supervised) | 76.5 | 190 |
| ImageNet-1K (supervised) | 72.6 | 202 |
| ImageNet-21K (supervised) | 72.0 | 197 |
DINOv2 outperforms supervised ImageNet by +3.9 pp AUC-ROC. Self-supervised representation quality matters more than label diversity for anomaly detection, and more categories (ImageNet-21K) don’t help.
GRU-based temporal modeling
A GRU query propagator maintains hidden state across frames to track temporal patterns. Compared to a simple linear projection baseline:
| Propagator | AUC-ROC | FPS |
|---|---|---|
| GRU | 78.1 | 200 |
| Linear | 76.3 | 189 |
The GRU improves AUC-ROC by +1.8 pp while maintaining comparable throughput.
The accuracy-efficiency trade-off

Our best model achieves 78.1% AUC-ROC at 200 FPS, which is 2.6× faster than Simple-TAD (85.2% at 76 FPS) but trails by 7.1 pp. All models far exceed the 30 FPS video rate.
| Model | AUC-ROC | FPS |
|---|---|---|
| Simple-TAD (VideoMAE-S) | 85.2 | 76 |
| VidEoMT-TAD ViT-S (Q=50, GRU) | 78.1 | 200 |
| VidEoMT-TAD ViT-S (Q=1, GRU) | 77.3 | 200 |
| VidEoMT-TAD ViT-S (Q=1, Linear) | 74.9 | 190 |
When to use image-pretrained models for TAD
Our findings suggest image-pretrained models are appropriate when:
- Latency-critical applications requiring >100 FPS, e.g., parallel multi-camera processing
- Resource-constrained edge devices where VideoMAE’s memory footprint is prohibitive
- Acceptable-accuracy scenarios where ~78% detection rate meets requirements, e.g., driver alert systems with human oversight
For safety-critical applications where high recall is required, video-pretrained models remain the better option.
Conclusion
This project investigated the trade-offs of using image-pretrained ViTs for traffic anomaly detection.
- Self-supervised pretraining provides better features than supervised pretraining for anomaly detection
- Lightweight temporal modeling (GRU) consistently improves over frame-independent baselines
- Image-pretrained backbones can close much of the gap to video-pretrained models while running significantly faster
Per-Category Analysis
Breaking down the accuracy gap by anomaly category:
| Category | Gap (pp) | Interpretation |
|---|---|---|
| Start/Stop | −4.5 | Static anomaly, spatial cues alone suffice |
| Obstacle | −7.3 | Stationary obstruction detected from single frame |
| Lateral | −7.7 | Side-to-side motion captured by spatial features |
| Oncoming | −8.9 | Focuses on the approaching hazard |
| Turning | −9.0 | Most common type, model attends to turning vehicle |
| Leave Left | −10.1 | Vehicle departing lane leftward |
| Moving Ahead | −10.5 | Forward collision detected through spatial proximity |
| Leave Right | −11.2 | Vehicle departing lane rightward |
| Unknown | −12.8 | Ambiguous scenarios requiring temporal context |
| Pedestrian | −16.4 | Hardest category, requires trajectory understanding |
Categories where the anomaly is spatially evident (a stationary obstacle, a stopped vehicle) have small gaps of −4.5 to −8.9pp. Categories requiring temporal reasoning (predicting a pedestrian’s trajectory, lane-departure dynamics) show larger gaps of −12.8 to −16.4pp.
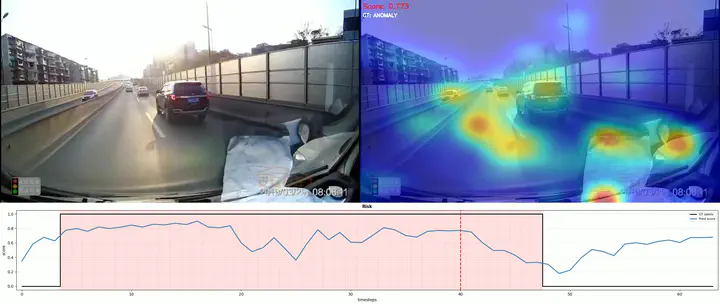
Attention Visualization
Aggregated attention heatmaps show where the model focuses, with confidence scores indicating anomaly probability.
Below are visualizations grouped by gap severity. Even for the hardest categories, the model attends to the correct regions, but the bottleneck is temporal dynamics, not spatial attention.
Small gap (−4.5 to −8.9pp)
Medium gap (−9.0 to −11.2pp)
Large gap (−12.8 to −16.4pp)
Temporal Modeling
Experiment 1: Impact of Frame Shuffle on AUC-ROC
VideoMT-TAD underperforms VideoMAE-based methods (Simple-TAD) on temporal anomaly detection despite using a query propagation mechanism (GRU updater) designed for temporal reasoning. We hypothesize the bottleneck is weak temporal modeling: the DINOv2 backbone processes each frame independently, and only the lightweight query tokens (50 out of 246 tokens) carry temporal information across frames. The 196 patch tokens, which carry 99% of the visual information, have zero cross-frame interaction.
To test this, we run a frame shuffle ablation: randomize frame order at inference while keeping everything else identical.
Results
| Metric | Normal Order | Shuffled | Drop |
|---|---|---|---|
| AUC-ROC | 0.7808 | 0.7397 | -4.1% |
| AUC-PR | 0.7194 | 0.6401 | -7.9% |
| Accuracy | 0.7327 | 0.6871 | -4.6% |
| F1 | 0.6228 | 0.6074 | -1.5% |
Interpretation
The model retains 74% AUC-ROC even with completely randomized frame order, losing only ~4%. This confirms that VideoMT-TAD’s performance is dominated by per-frame DINOv2 features (spatial stream), with the GRU query propagation contributing minimally to the final prediction. The temporal modeling pathway, which only operates on the small query token subspace, fails to capture meaningful motion or temporal dynamics from the much richer patch feature space.
Experiment 2: Spatial Attention Consistency (Ordered vs Shuffled)
VideoMT-TAD uses a query propagation mechanism where queries are updated frame by frame through a GRU updater. The key question is: does this temporal propagation actually help queries maintain spatial focus on the same region across frames, or is the spatial consistency simply a byproduct of visual similarity between consecutive frames?
To disentangle these two factors, we run the model under two conditions:
- Ordered: frames fed in their natural temporal order (GRU state accumulates coherent temporal context)
- Shuffled: frames randomly permuted before feeding to the model (GRU state receives incorrectly ordered inputs)
We measure the IoU of the top 16 attended patches between what the model processes as “consecutive” frames (frame processed at step t vs step t+1).
Results
| Normal clips | Anomaly clips | All | |
|---|---|---|---|
| Ordered IoU | 0.473 | 0.366 | 0.426 |
| Shuffled IoU | 0.326 | 0.226 | 0.282 |
| Delta | +0.147 | +0.139 | +0.144 |
Interpretation
- The GRU query updater (Query Fusion mechanism) does contribute to spatial tracking. Ordered input yields ~14% higher IoU than shuffled, confirming that temporal propagation helps queries maintain consistent spatial focus across frames.
- But the tracking improvement is class-agnostic. The delta between ordered and shuffled is nearly identical for normal clips (+0.147) and anomaly clips (+0.139). This means the GRU updater tracks regions equally for both classes; it does not adapt its tracking behavior based on whether the scene is normal or anomalous. This is expected, as VidEoMT was designed for instance segmentation where class-agnostic tracking consistency is important.
- The query mechanism detects spatial change but cannot interpret it. Anomaly clips consistently have lower IoU than normal clips under both conditions (ordered: 0.366 vs 0.473; shuffled: 0.226 vs 0.326). This means queries do shift attention when visual disruption occurs during anomalies. However, this attention shift does not translate into an effective anomaly detection signal: the model notices “something changed spatially” but cannot determine “this change could lead to an anomaly.”
In summary: the query updater successfully maintains spatial tracking across consecutive frames, but this tracking is a generic visual correspondence mechanism rather than an anomaly-aware temporal reasoning module.
Experiment 3: Cross-Frame Temporal Attention
The frame shuffle ablation revealed that VideoMT-TAD’s temporal modeling contributes only ~4% AUC-ROC. A key architectural limitation is that the 196 patch tokens are processed independently per frame, meaning only the query tokens propagate across frames. As a result, the temporal pathway has no direct access to fine-grained visual changes in the patch feature space.
To address this, we add a post-backbone cross-frame attention module: query tokens cross-attend to patch tokens from all frames (with causal masking, so frame t only sees frames 0..t).
Results (ViT-S, Q=1)
| Config | AUC-ROC |
|---|---|
| Baseline (Q=1, DINOv2) | 76.5% |
| + Cross-Frame Attention (2 layers, 6 heads) | 76.7% |
Under this setting, adding cross-frame attention leads to no meaningful improvement (+0.2%).
Interpretation
The lack of improvement in this particular configuration suggests that simply routing patch information to queries with cross-attention may not be sufficient. Several factors could limit the effectiveness:
- Single query (Q=1) may lack the representational capacity to absorb rich cross-frame patch information. With more queries, the module may have more slots to capture different temporal patterns.
- ViT-S (384 dims) is relatively small; the cross-attention module may benefit more from larger backbone capacity (ViT-B/L) where patch features carry richer representations.
- Hyperparameter sensitivity: the cross-frame experiment used the same training settings (LLRD, warmup schedule), which may not be optimal for this module.
Experiment 4: ST-Adapter with Frozen DINOv2 vs. Simple-TAD Baselines
We add ST-Adapters (spatiotemporal convolution adapters with reduction factor 8, kernel size 3) into the ViT-S backbone blocks while keeping DINOv2 weights frozen (unlike previous experiments, which fine-tuned the DINOv2 backbone with a lower learning rate). Only the adapters, GRU query updater, and classification heads are trained. This allows the patch tokens, which previously had zero cross-frame interaction, to gain temporal modeling capacity through the adapter’s temporal convolutions.

Results
| Method | Backbone | Pretrain | AUC-ROC | Total Params | Trainable Params |
|---|---|---|---|---|---|
| VidEoMT-TAD-S (ST-Adapter) | ViT-S | DINOv2 (frozen) | 81.3% | 23.3M | 1.3M |
| Simple-TAD (VideoMAE) | ViT-S | VideoMAE K400 | 83.7% | 21.9M | 21.9M |
| Simple-TAD (VideoMAE2) | ViT-S | VideoMAE2 K710 distill | 86.0% | 21.9M | 21.9M |
| Simple-TAD (MVD) | ViT-S | MVD K400 (teacher ViT-L) | 85.3% | 21.9M | 21.9M |
| Simple-TAD (DAPT) | ViT-S | DAPT BDD+CAP → K400 | 86.4% | 21.9M | 21.9M |
ST-Adapter Frame Shuffle Ablation
We evaluate whether the ST-Adapter variant is sensitive to temporal order by shuffling frames at inference.
| Metric | Normal | Shuffled | Drop |
|---|---|---|---|
| AUC-ROC | 0.8087 | 0.7458 | -6.29% |
| AUC-PR | 0.7465 | 0.6254 | -12.11% |
| Accuracy | 0.7527 | 0.6830 | -6.97% |
| F1 | 0.6459 | 0.6251 | -2.08% |
The ST-Adapter variant shows a larger AUC-ROC drop when frames are shuffled (-6.29% vs -4.11%), confirming that the Conv3D(3×1×1) adapters learn meaningful temporal representations beyond what the GRU query updater alone captures. Notably, both models converge to similar shuffled performance (~0.74), suggesting this reflects a shared floor set by single-frame spatial features. The ST-Adapter’s +2.8% improvement over the baseline is therefore almost entirely attributable to temporal modeling, it is effectively erased when temporal order is destroyed.
Comparison with Other DoTA Methods
| Method | Input | AUC-ROC | Total Params |
|---|---|---|---|
| FOL-Ensemble | RGB+Box+Flow+Ego | 73.0% | — |
| STFE | RGB+Box (two-stage) | 79.3% | — |
| VidEoMT-TAD-S (ST-Adapter) | RGB only | 81.3% | 23.3M |
| MOVAD | RGB only | 82.2% | ~114M |
| TTHF | RGB+Text | 84.7% | ~452M |
Efficiency Comparison (Streaming FPS on Nvidia Titan V)
| Config | AUC-ROC | Streaming FPS |
|---|---|---|
| VidEoMT-TAD-S (GRU Q50, no adapter) | 78.1% | 200 |
| VidEoMT-TAD-S (GRU Q50 + ST-Adapter) | 81.3% | 112 |
| Simple-TAD trained on DoTA (VideoMAE ViT-S) | 83.7% | 76 |
The ST-Adapter improves AUC-ROC by +3.2% but reduces streaming throughput by 44% (200 to 112 FPS). This slowdown comes from the ST-Adapter’s depthwise Conv3D, which requires maintaining a causal buffer of the previous frame’s downprojected features per block, by adding 9 extra convolution operations (one per transformer block before the segmenter) per frame during streaming inference. However, during inference only the new frame’s patch tokens are processed through the DINOv2 backbone; previous frames’ patch features are cached and reused. Still, both VideoMT-TAD variants are faster than Simple-TAD (76 FPS), which must process all 1,568 spatiotemporal tokens jointly through full self-attention. The ST-Adapter model achieves 1.5× the throughput of Simple-TAD while closing the AUC-ROC gap to 2.4%.
Note: The results of ST-Adapter are preliminary and have not been optimized. Different hyperparameter configurations may have better performance.
Resources
Citation
@article{Norouzi2026VidEoMT,
author = {Norouzi, Narges and Zulfikar, Idil and Cavagnero, Niccolo and Kerssies, Tommie and Leibe, Bastian and Dubbelman, Gijs and {de Geus}, Daan},
title = {{VidEoMT: Your ViT is Secretly Also a Video Segmentation Model}},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2026},
}
@inproceedings{Orlova2025SimpleTAD,
author = {Orlova, Svetlana and Kerssies, Tommie and Englert, Brun{\'o} B and Dubbelman, Gijs},
title = {{Simplifying Traffic Anomaly Detection with Video Foundation Models}},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
pages = {852--862},
year = {2025},
}
@article{Kerssies2025EoMT,
author = {Kerssies, Tommie and Cavagnero, Niccolo and Hermans, Alexander and Norouzi, Narges and Averta, Giuseppe and Leibe, Bastian and Dubbelman, Gijs and {de Geus}, Daan},
title = {{Your ViT is Secretly an Image Segmentation Model}},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025},
}
Acknowledgment
This work was conducted at the Mobile Perception System lab, Eindhoven.
Chengqi (William) Li
My research interests include 3D perception, computer vision, and deep learning.