YourArXiv.com -- a Personalized ArXiv with Embedding based recommendation
 YourArXiv.com
YourArXiv.comIntroduction
This application is a personalized ArXiv recommendation system that uses a language model to generate embeddings for papers and calculates the similarity between papers to recommend papers that are similar to the ones that the user has liked.
Application architecture
The web application consists of five primary components, which interact with each other to provide the necessary functionality, including background processes:
- A Flask-based backend for API hosting
- A React-based front-end that interacts with users and the backend server
- Lambda function-based background processes triggered by time to collect the latest papers and generate embeddings
- An S3-based file system for storing the embedding dataset used for similarity calculations
- A DynamoDB-based database for managing user information and paper metadata
Frontend design
We used the React framework to create a responsive and dynamic user interface for our front-end page. To improve our data visualization capabilities, we integrated both Three.js and Plotly libraries. These tools enable us to generate informative and interactive visualizations effortlessly for keywords and trend plots.
Database schema
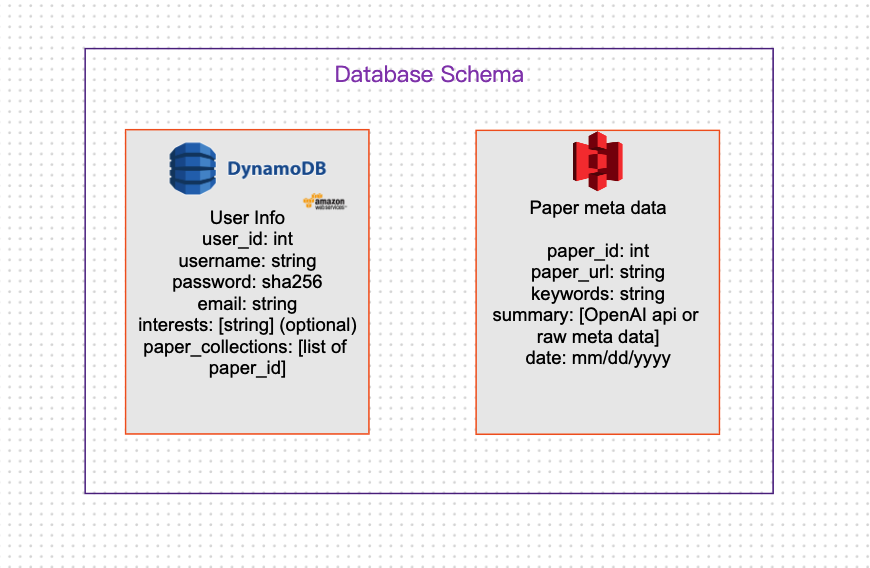
scan or query functions. However, we chose to store the embedding information in S3 due to its scalability and cost-effectiveness. Retrieving the embedding information from DynamoDB would become extremely slow as the number of papers increases. Our approach involves using DynamoDB for serving data lookup requests while S3 serves as the foundation of our recommendation system.
Recommendation system
The recommendation system for YourArXiv is based on the Ada2 model, which is a language model that uses a transformer encoder to generate embeddings for text input. We use the embeddings generated by the model to calculate the similarity between papers and recommend papers that are similar to the ones that the user has liked. To speed up the process, we built a Nearest Neighbor search system with scikit-learn’s BallTree algorithm. The system is deployed as an AWS Lambda function and is triggered by a timer to update the embedding dataset every 24 hours.
Deployment
The frontend is build to static files and hosted on AWS S3. The backend is deployed on our own EC2 instance.
For the backend part, we use Gunicorn as the WSGI server and Nginx as the reverse proxy. The following is the command to start the backend server:
gunicorn --workers=2 --bind=127.0.0.1:8000 backend.app:app --timeout 600
The Gunicorn server runs on localhost port 8000 which cannot be accessed from the Internet directly. It is then proxied by Nginx.
First, Install Nginx:
sudo apt-get install nginx
Then, modify the Nginx configuration file under /etc/nginx/sites-available. Create a new file named yourarxiv and add the following lines:
server {
listen 80;
server_name yourarxiv.com www.yourarxiv.com;
location / {
proxy_pass http://127.0.0.1:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
Then create a soft link to the sites-enabled folder:
sudo ln -s /etc/nginx/sites-available/myproject /etc/nginx/sites-enabled
Follow the steps in https://www.digitalocean.com/community/tutorials/how-to-serve-flask-applications-with-gunicorn-and-nginx-on-ubuntu-22-04 to configure HTTPS.
For more details, please checkout our paper:
Collaborators: William Li, Ginne Zhang, Haoxiang Ning
Chengqi (William) Li
My research interests include 3D perception, computer vision, and machine learning.